We are announcing the launch of Soniox v4 Async, a major leap forward for speech recognition technology. For years, the promise of speech AI has been fragmented—great for English, passable for major languages, and barely usable for everything else.
Today, we are erasing that divide.
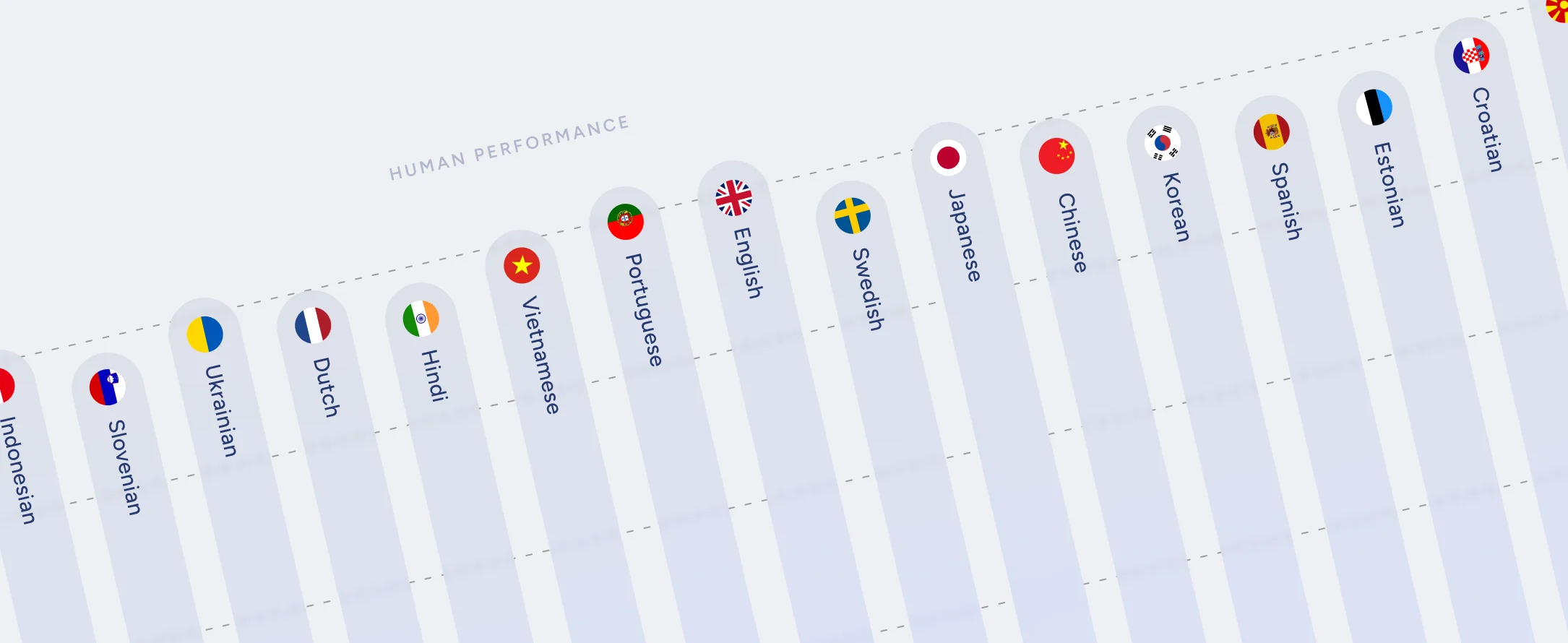
Soniox v4 Async is not just an incremental update; it delivers human-parity accuracy across 60+ languages. It is the first speech AI designed to understand the world as it truly speaks: fluently, contextually, and interchangeably.
1. Human parity for the world (not just English)
The most significant breakthrough in v4 is reaching or exceeding human-parity accuracy for over 60 languages.
What does "human parity" really mean? It means the AI recognizes speech with the same precision as a native speaker of that language. For the first time, a user speaking Japanese, Korean, Slovenian, Swedish, Hungarian, or Arabic gets the same "native-speaker" quality that was previously reserved only for English.
Why this matters: For businesses, this effectively kills the "edit tax." Historically, companies using speech AI for non-English markets had to hire humans to heavily edit and correct the AI's mistakes. With Soniox v4 Async, the transcript is accurate by default. Whether it’s a complex legal deposition in Swedish or a fast-paced business meeting in Korean, the output is ready for immediate use.
2. One model, every language
Traditional providers force you to select a language model before you process a file (e.g., model='en-US'). If the audio turned out to be French, the transcription failed.
Soniox v4 Async completely removes this friction. We do not use a "Language Identification (LID) + Speech-to-Text" patchwork. Soniox v4 Async is a single, universal AI model that natively understands all 60+ languages.
This architecture allows the model to handle code-switching (switching languages mid-sentence) seamlessly. If a speaker starts a sentence in Hindi and finishes it in English (Hinglish), or switches between Spanish and English, v4 doesn't just detect the switch; it follows the meaning across the language barrier without missing a beat.
3. Deep context
While context features aren’t new, Soniox v4 Async implements them in a fundamentally new and far more effective way, delivering a major step forward in how speech models use context to improve accuracy.
Most legacy engines handle context (like boosting specific keywords) by manually biasing the decoding stage—a "hacky" post-processing step that often breaks grammar. Soniox v4 Async takes a different approach. Because our architecture is transformer-based with deep attention mechanisms, the model has learned how to pay attention to context automatically.
When you provide context (even a large one, up to 8,000 tokens) the model ingests it just like a human reads a briefing document before a meeting. It uses that context to resolve ambiguities during the recognition process, not after.
The impact: We are seeing customers achieve human-level medical transcription accuracy by passing patient history and terminology as context. This capability is saving millions of dollars by eliminating the need for human review. In many workflows, humans now only review the tiny percentage of documents where the AI's confidence score is low, automating 95%+ of the workload.
4. Simultaneous transcription & translation
With Soniox v4 Async, we further improved our "2-for-1" capability: transcribe and translate in a single API call.
If you have a 3-hour recording in French, one call to the Soniox API will return:
- A highly accurate French transcript.
- A highly accurate translation into any of the other 60+ languages.
We have applied the same rigor to our translation engine as our transcription engine. We focused heavily on equalizing quality, ensuring that translation into smaller languages is just as fluid and accurate as translation into major ones.
5. Ready for production
Soniox v4 Async model is available immediately via our API. It is built for heavy-duty enterprise workloads, supporting files up to 5 hours in duration. Whether you are archiving years of media or processing daily call center logs, v4 is ready to scale.
Soniox v4 Async is fully backward-compatible with Soniox v3 Async. To upgrade, simply change the model name to stt-async-v4 and you’ll immediately get all the benefits of v4.
Try Soniox v4 Async today
We believe that language should never be a barrier to technology. With v4, we haven't just built a better speech recognition model; we've built a foundation for global understanding.