Turn live conversations into structured intelligence.
Trusted by teams building global voice products
Multilingual voice AI for real-time applications
Power your products with speech-to-text, text-to-speech, and real-time translation in 60+ languages through one unified API.

Transcribe in real-time
Transcribe speech in real time across 60+ languages, with native-speaker accuracy for multilingual, language-switching, and multi-speaker conversations.
Explore Speech-to-Text API
Generate natural speech
Generate natural, high-fidelity speech in 60+ languages, with precise handling of alphanumerics, names, borrowed words, and language switching.
Explore Text-to-Speech APITranslate in real-time
Translate speech in real time across 3,600 language pairs, with low-latency output before sentences finish and high-quality multilingual results.
Explore Speech Translation APIBuilt for the hardest parts of voice AI
Most voice platforms were built for English first. Soniox is built for high accuracy across 60+ languages, seamless language switching, alphanumerics, and low-latency interaction.
World’s most accurate speech-to-text
Unmatched recognition accuracy across languages, accents, numbers, names, and domain-specific vocabulary, engineered for fast, multi-speaker conversations and high-noise environments.
Text-to-speech built for precision
Generate high-fidelity, hallucination-free speech in 60+ languages. Built for the hardest production TTS challenges: alphanumerics, foreign names, language switching, and ultra-low-latency streaming.
Hi there! This is the appointment line for Dr. Okafor's office. Um, I'm calling to confirm your visit on Tuesday the 14th at 2:30.
Low-latency streaming for live interaction
Transcribe speech with sub-200ms latency and start generating audio from the first few words, before the full sentence is available.
Stop stitching together voice providers. Build with one platform for speech-to-text, text-to-speech, and translation in 60+ languages.
Powering the world's most demanding products
From global enterprises to frontier AI labs, teams choose Soniox for the accuracy, speed, and scale their products demand.
Perplexity integrated Soniox to power a best-in-class voice experience for millions of Perplexity users.
A global technology leader using Soniox across internal meetings, call centers, and government projects in Korea.
Using Soniox for real-time captions and voice interactions, helping bring faster and more natural speech experiences to users.
Using Soniox to power transcription and real-time speech translation across meetings and contact center products.
An enterprise AI agent platform, using Soniox to power voice AI agents across non-English markets where best-in-class voice AI is scarce.

Pioneers in AI-powered healthcare technology, dedicated to transforming the way healthcare providers deliver care.
Using Soniox for best-in-class real-time captioning in its widely used meeting notes platform.
Uses Soniox voice AI to power human-quality voice agents with exceptional accuracy, speed, and reliability, across languages and at massive scale.
Trusted by millions of people worldwide, using Soniox to power highly accurate transcription for phone calls and voice messages across multiple languages.
“It just gets the words right — any language, any accent, any context. That’s what accuracy is supposed to look like.”
Tony Wang
Cofounder & Chief Revenue Officer at Agora
“We tried a dozen speech-to-text and translation services. Soniox is the best, so that's what we use.”
Cayden Pierce
CEO/CTO at Mentra
A fast-growing real-time translation app, using Soniox to power low-latency speech translation for seamless multilingual communication.
“As Germany’s leading voicebot provider for automotive dealerships, Soniox has transformed our recognition of customer IDs and alphanumerics, driving much higher voicebot acceptance rates.”
Dr. Steven Zielke
Founder & CEO of mobilApp
“It’s so fast, captions appear before people even finish talking. Zero lag. No buffering. Nothing.”
Dag-Inge Aas
Head of AI at Tana
Built for agents, dictations, and everything in between
From real-time conversations to large-scale workflows, Soniox gives developers a complete speech platform for building fast, accurate, multilingual voice products.
Voice agents
Power conversational AI with low-latency speech recognition and natural speech output built for responsive, human-like interactions.
Wearables
Deliver live voice experiences on devices that need streaming speech recognition and speech generation with minimal delay.

Speech translation
Build speech-to-text or speech-to-speech translation directly into your product.
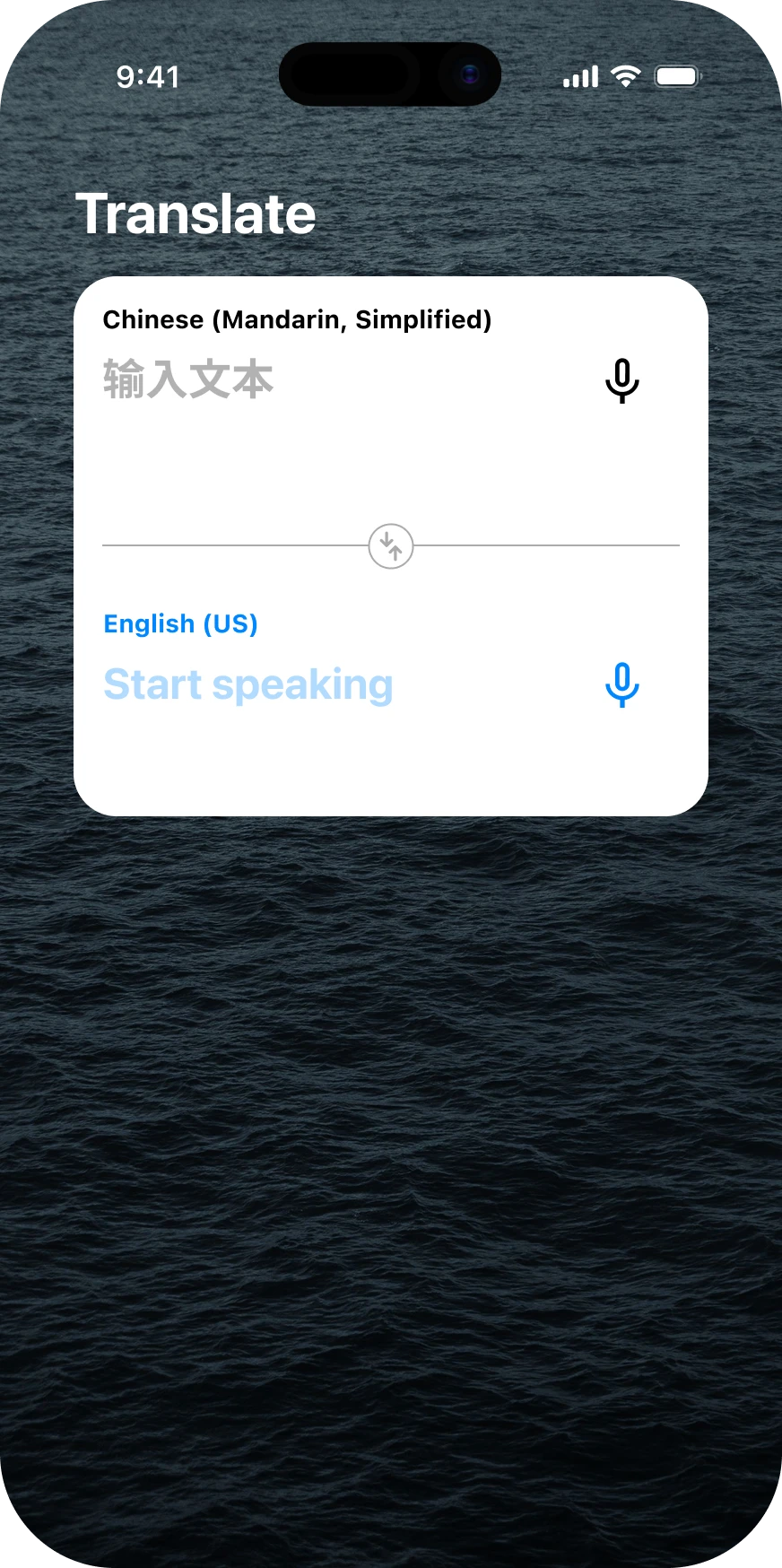
Dictation and voice typing
Turn speech into clean, reliable text for messages, notes, documents, and workflows where accuracy matters.

New Note
Today · 8:20 PM
Build the next generation of voice products, from agents and wearables to dictation, translation, and real-time multilingual experiences.
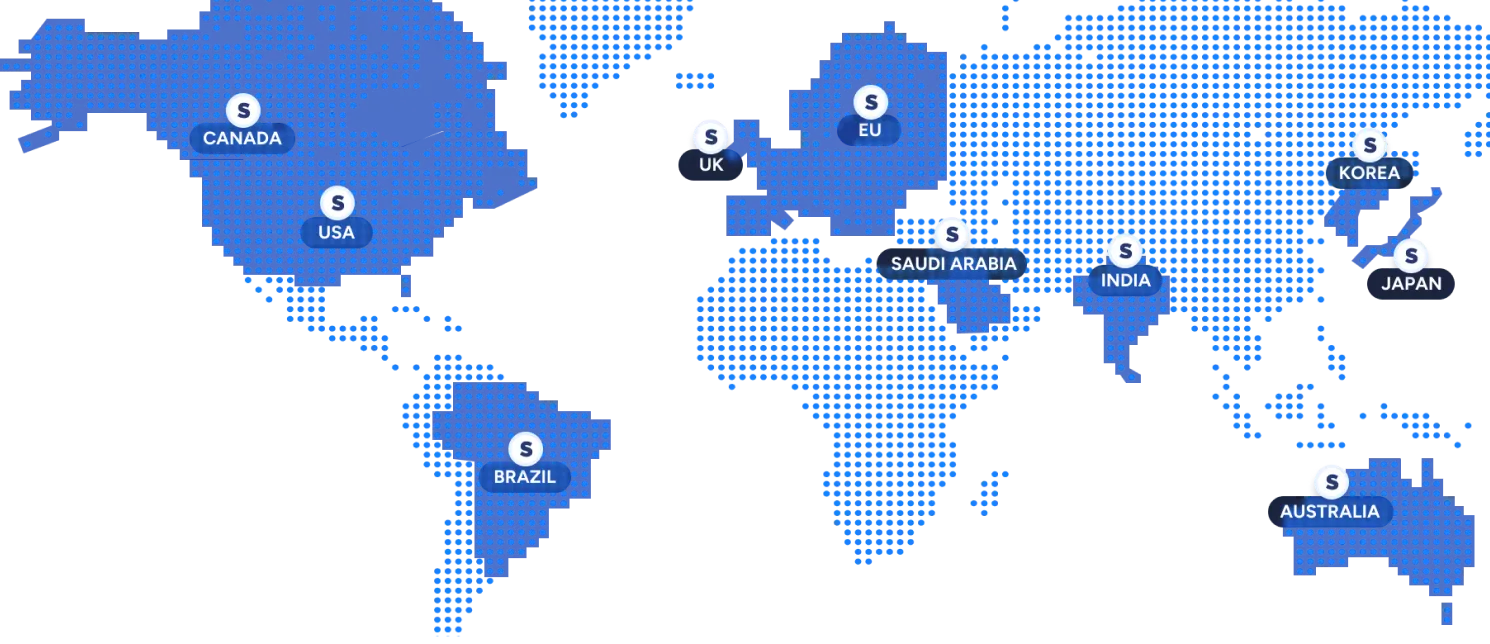
One global API, deployed locally
Use the same models and API everywhere, with in-region processing to meet latency, data residency, and regulatory requirements.
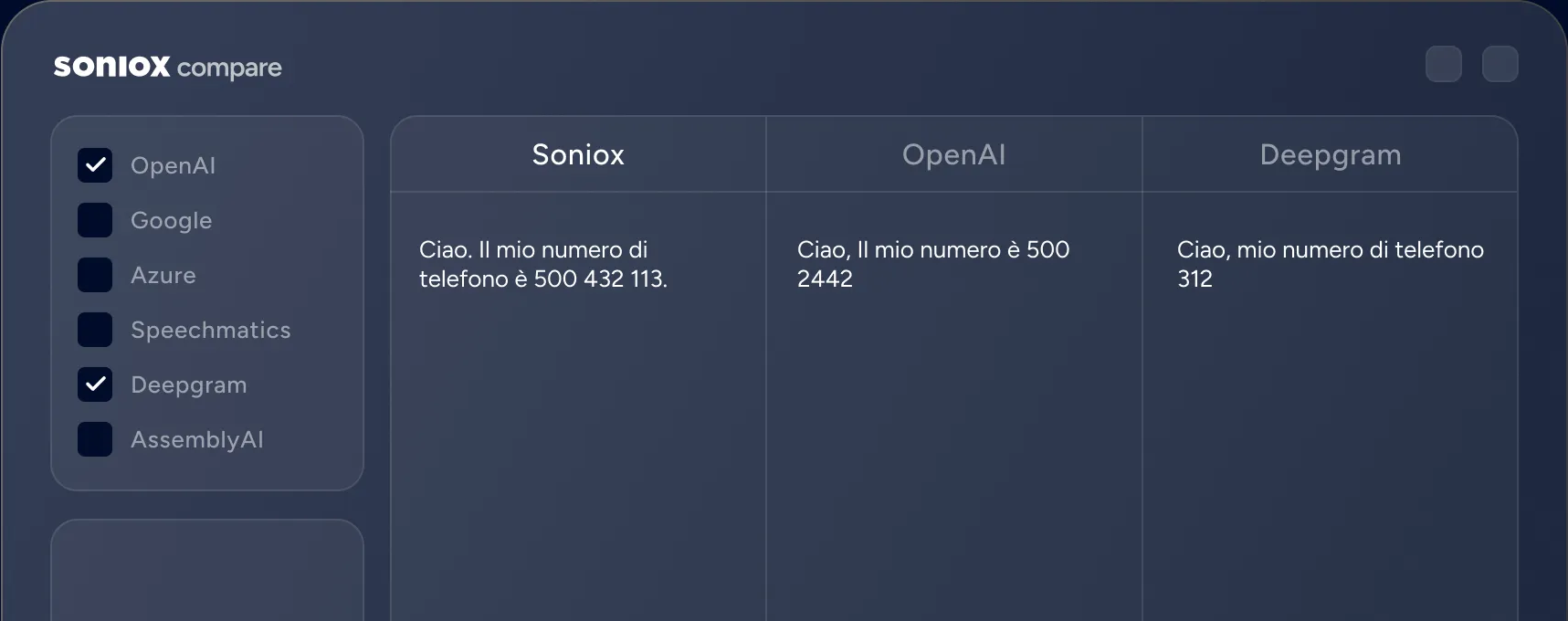
Soniox Data ResidencyCompare Soniox side by side
Compare Soniox side by side with other providers across speech-to-text and text-to-speech. Live inputs. Transparent results.
Latest news from Soniox
Privacy and compliance, built right in
Never stored, never saved.
Audio stays in memory, everything is processed in real-time.
Built for privacy-critical use cases.
Adhering to leading global security, privacy, and compliance standards.
Trusted where privacy matters most.
Used in industries where speech is sensitive, from healthcare to enterprise.




Frequently asked questions
What is Soniox?
What does “speech AI” mean?
What can I do with the Soniox App?
- Translate speech in real time between languages
- Dictate text into any app or text field
- Capture meetings, notes, and ideas automatically
What’s the difference between the Soniox App and the API?
Does Soniox offer a general-purpose speech-to-text API?
Can Soniox handle mixed languages in the same conversation?
Can Soniox distinguish between different speakers?
Is Soniox suitable for developers and enterprise use?
- High accuracy across accents and domains
- Scalable infrastructure
- Enterprise-grade security and compliance options
What makes Soniox different from other speech-to-text solutions?
- Real-time transcription without waiting for sentence boundaries
- Mixed-language support
- Strong handling of numbers, names, and domain-specific terms
- A single platform powering both an app and an API
Do I need to be a developer to use Soniox?
How do I get started?
- Build with API to integrate Soniox into your product or workflow
Ready to get started?
Create an account instantly, or contact us to design a custom package for your business.
Build with APIDocumentation
Get up and running in minutes and spend your time building, not wrestling with the API.
Explore docsSee what you’ll pay
Pay only for what you use with our flexible pricing. Built to scale with you.
Pricing details