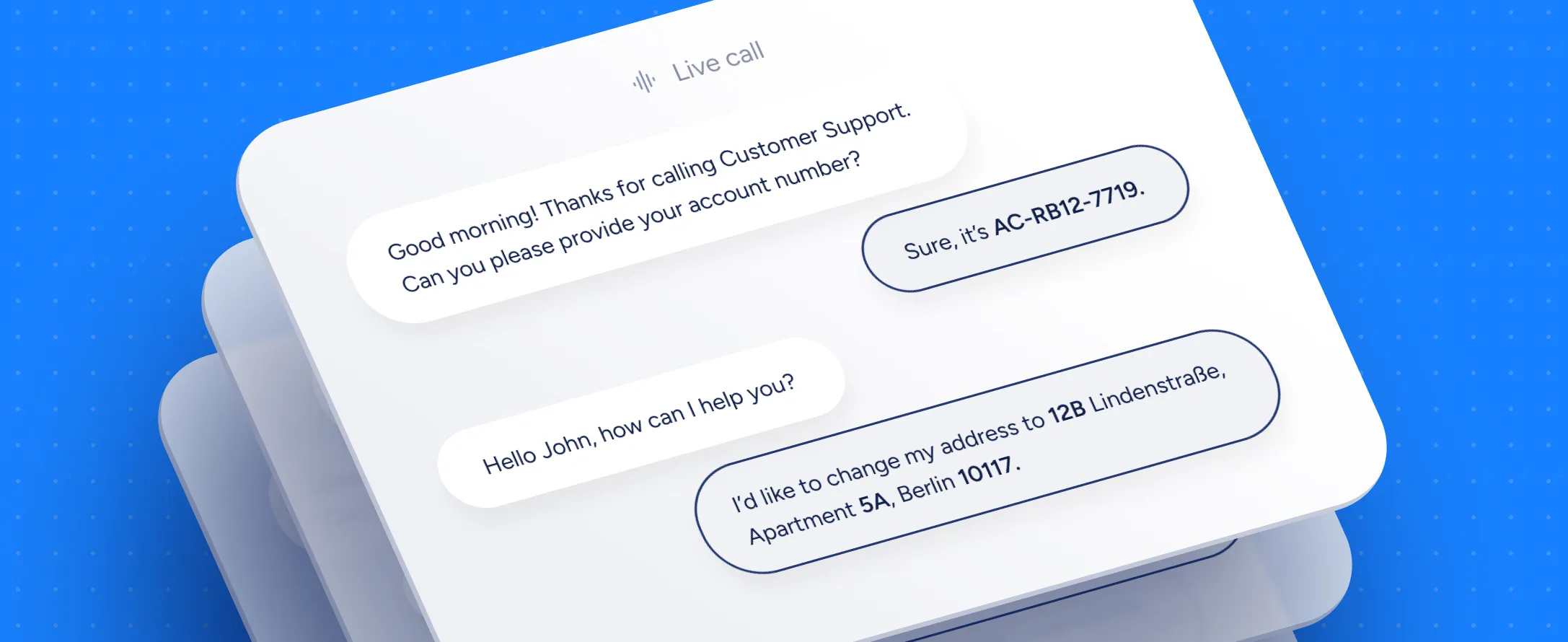
Today, we’re releasing Soniox v4 Real-Time, a speech recognition model purpose-built for low-latency voice interactions.
Unlike traditional STT systems that trade accuracy for speed or are optimized around a single language at a time, Soniox v4 delivers native-speaker accuracy across 60+ languages with no trade-offs. It’s built for mission-critical voice agents, live captioning, and real-time global communication, setting a new standard for real-time speech AI.
Soniox v4 Real-Time is built for teams shipping voice-first products where latency, accuracy, and multilingual reliability are non-negotiable.
1. Native-speaker accuracy across 60+ languages
For too long, speech AI has been built with an English-first mindset, with all other languages treated as secondary. Soniox v4 changes that.
Soniox v4 reaches native-speaker accuracy across 60+ languages simultaneously. We didn’t just optimize for a handful of major languages, we equalized the product experience across every supported language. Whether your users speak French, Hindi, Portuguese, or Japanese, they receive the same level of accuracy and reliability that was previously available only for English.
In real-time voice interactions, “close enough” isn’t good enough. A single missed word can break the flow of a conversation or derail an action. Soniox v4 provides the high-fidelity foundation required for AI systems to converse naturally, without constant interruptions or recovery prompts.
2. Millisecond finality: Speed without sacrifice
In conversation, a 500 ms delay feels like an eternity. For a voice agent to feel alive, the transition from speech to text must be nearly instantaneous.
Soniox v4 delivers industry-leading low latency for final transcriptions, producing high-accuracy final text just milliseconds after speech ends. This allows your system to trigger the next action, whether that’s a LLM prompt or a spoken response, before the user even wonders if the AI is listening.
For applications that require explicit control, Soniox v4 also supports manual finalization. This lets you decide exactly when audio should be finalized, instead of relying on automatic endpoint detection. Manual finalization is particularly useful for push-to-talk systems, client-side voice activity detection (VAD), segment-based transcription pipelines, and workflows where automatic endpoint detection is not ideal. Once a <finalize> command is issued, Soniox returns the high-accuracy final transcript in just milliseconds, enabling immediate downstream actions with no perceptible delay.
3. Semantic endpointing: Listen like a human
Traditional Voice Activity Detection (VAD) is a blunt, acoustic tool. It listens for silence and cuts the audio when the pause lasts too long. That’s why AI assistants often interrupt you while you’re slowly reading a phone number or an address.
Soniox v4 introduces semantic endpointing. Instead of relying on silence alone, the model understands context, rhythm, and intent. Endpointing shifts from an acoustic problem to a semantic one.
-
The VAD way:
You say: “555… [pause] …0192” → the system cuts you off. -
The Soniox way:
The model understands the sequence is incomplete and waits patiently. When it detects real conversational finality, it ends the turn immediately.
This results in fewer interruptions, lower downstream compute costs, and a more natural conversational experience across your entire voice stack.
In addition to semantic endpointing, Soniox v4 lets you fine-tune when that endpoint is returned. The model still decides whether an utterance is complete based on meaning, context, and intent, but max_endpoint_delay_ms gives you control over the maximum time the system will wait before emitting that endpoint once speech has ended. Lower values bias toward faster turn-taking, while higher values allow more patience for deliberate pauses. This way, semantic understanding drives endpoint decisions, while timing remains fully adjustable to match your product’s responsiveness requirements.
4. Real-time speech translation, without waiting for the sentence
With the Soniox API, you can transcribe and translate speech simultaneously in a single real-time stream.
Unlike sentence-level systems that wait for an utterance to complete, Soniox translates speech in low-latency streaming chunks. As a speaker talks, translations appear continuously, keeping pace with the conversation instead of lagging behind it.
Delivering high-quality translation under these constraints is difficult. Streaming translation requires the model to commit early, before full sentence context is available, while still preserving meaning, grammar, and intent. Soniox v4 was engineered to optimize latency and quality jointly, rather than trading one for the other.
As a result, translation quality has been significantly improved across both major and minor languages, with consistent performance across 3,600 language pairs. The experience feels truly real time, not end-of-sentence, not rewritten after the fact, enabling live subtitles, natural multilingual conversations, and voice agents that can respond immediately across languages.
5. Built for the enterprise
Soniox v4 Real-Time is available immediately via API and engineered for demanding, enterprise-grade workloads. It supports uninterrupted real-time audio streams of up to 5 hours, enabling long-running voice agents, live events, and continuous transcription or translation in production environments.
v4 Real-Time is fully backward-compatible with Soniox v3 Real-Time. Upgrading requires no architectural changes, simply switch the model name to stt-rt-v4 and immediately benefit from improved accuracy, lower latency, and increased reliability.
The practical shift
Soniox v4 Real-Time isn’t about adding features, it’s about removing the friction that has historically made real-time voice AI hard to deploy globally.
By solving for latency, language parity, and semantic understanding at the model level, we’re providing the infrastructure needed for reliable, human-like voice systems.
You can start building with Soniox v4 Real-Time today via the Soniox API.