Build agents and applications that understand speech in any language
The world’s most accurate real-time speech-to-text and translation API, powering voice agents, live systems, and applications across 60+ languages.
“It just gets the words right — any language, any accent, any context. That’s what accuracy is supposed to look like.”
Tony Wang,
Cofounder & Chief Revenue Officer at Agora
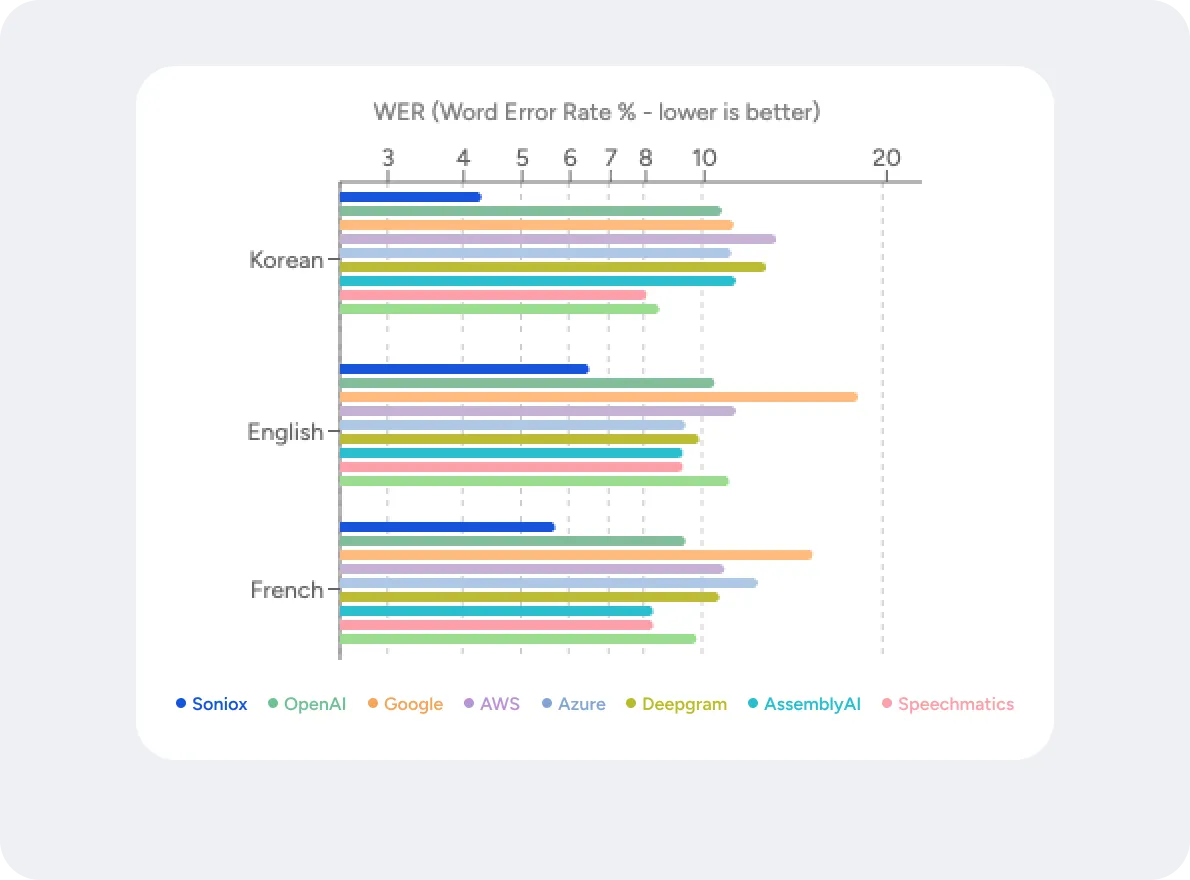
Recognize speech with native-speaker accuracy across 60+ languages
"We tried a dozen speech-to-text and translation services. Soniox is the best, so that's what we use."
Cayden Pierce,
CEO/CTO at Mentra

Handle language switching mid-sentence
"It’s the first model we’ve used that actually understands Hinglish. Switching mid-sentence just works."
Prakash N,
Co-Founder & Director at Tevatel
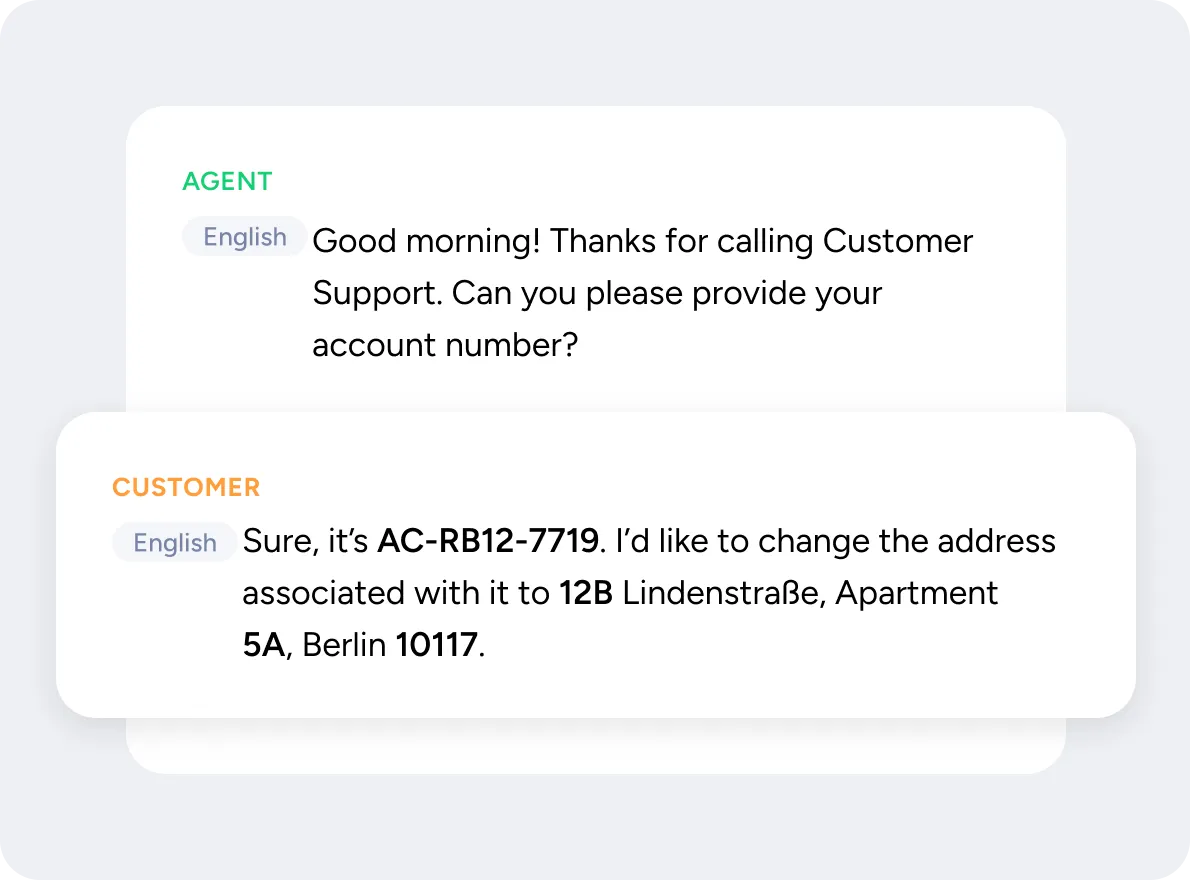
Capture alphanumerics like emails, addresses, and phone numbers
"As the leading provider of voicebots for automotive dealerships in Germany, we’ve faced significant challenges recognizing license plates accurately. Soniox has solved this problem with exceptional recognition of alphanumeric sequences, resulting in a much higher acceptance rate for our voicebot."
Dr. Steven Zielke,
Founder & CEO of mobilApp
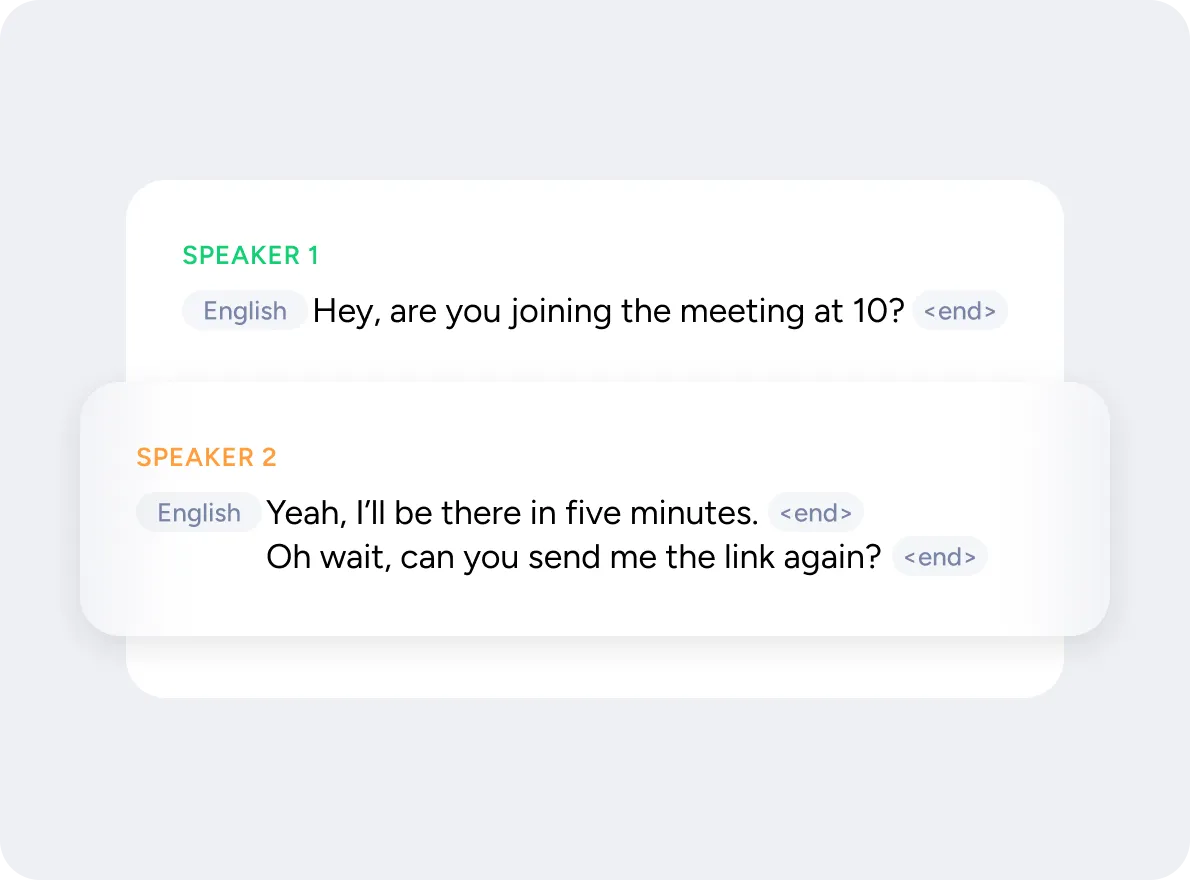
Detect when a speaker has finished speaking
"It’s so fast, captions appear before people even finish talking. Zero lag. No buffering. Nothing."
Dag-Inge Aas,
Head of AI at Tana
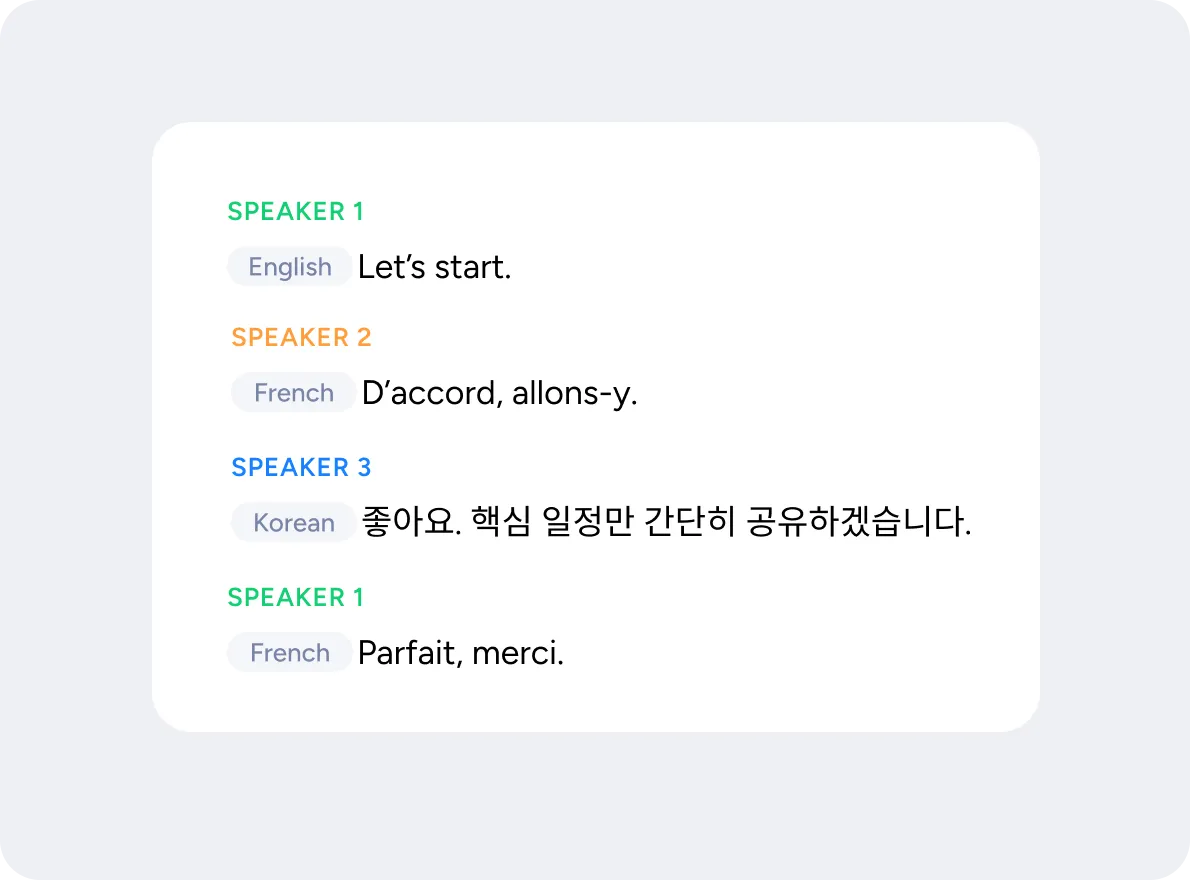
Separate and identify speakers across 60+ languages
"Live multilingual meetings finally sound natural, Soniox translates fluidly, in real-time."
VP of engineering at leading AI assistant company

Improve accuracy with domain-specific context
"Soniox's ability to accurately transcribe complex medical terminology means our physician-customers spend significantly less time editing. This allows them to finalize their notes faster and focus on what matters most: patient care."
Max Malyk,
Vice President at DeliverHealth
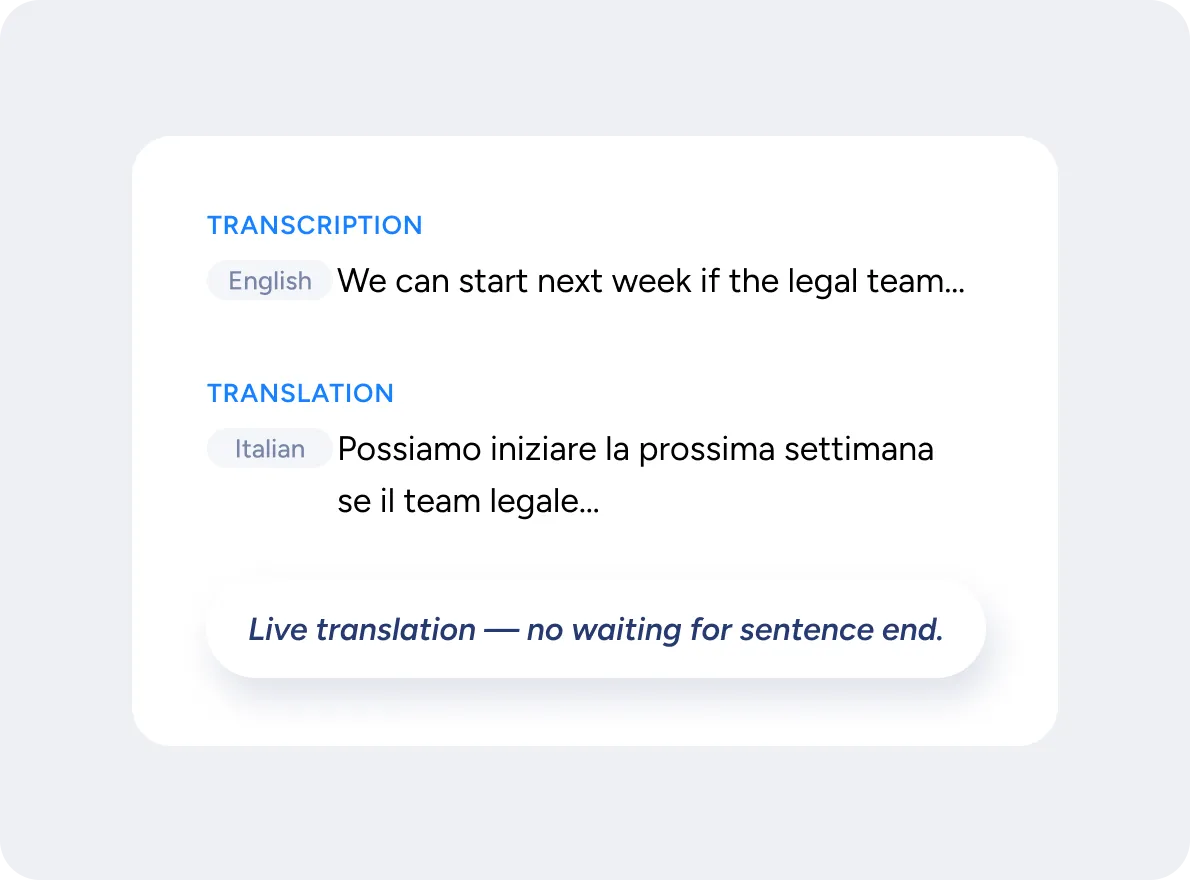
Translate speech as people speak, not after they finish
3,600 language pairs supported.
Soniox delivers the world’s first true real-time, any-to-any speech translation – translating as people speak, not after they finish. Unlike other systems that wait for full sentences or support only one-way pairs, Soniox streams mid-sentence translations continuously between 60+ languages, in every possible combination. The result is low-latency, high-quality translation that sounds natural and immediate.
"It just gets the context — and when we add our own domain knowledge, it feels completely customized to us."
Mark Boyce,
CEO at MediLogix
Speech infrastructure for massive scale
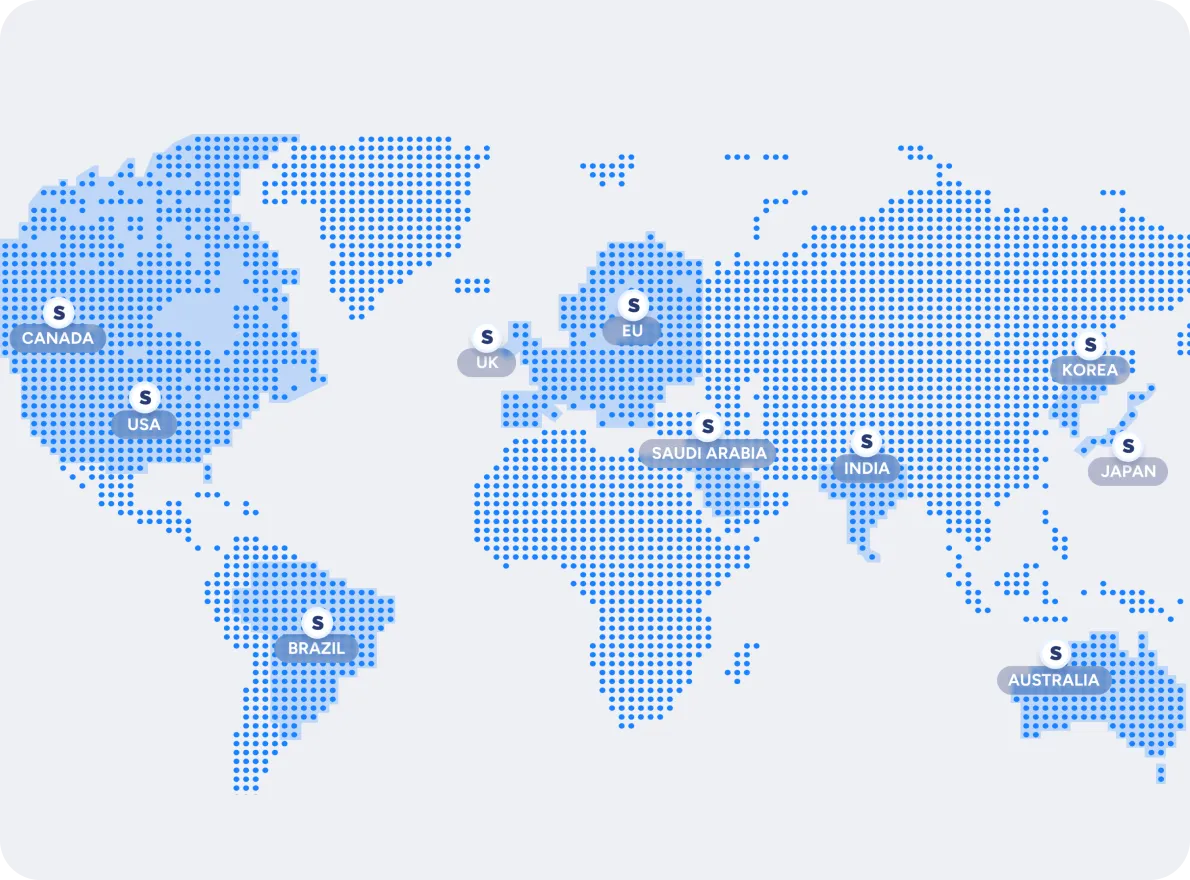
Build on one API and deploy in your region
Soniox processes and stores speech data entirely within your selected region, using the same models and APIs everywhere. This ensures data residency, regulatory compliance, and low-latency performance for local users.
Available: US, EU, Japan
Coming soon: Korea, Australia, Canada, India, Saudi Arabia, UK, Brazil
"Before Soniox, our international users always had a noticeably different experience. Now accuracy and responsiveness match across all regions…it feels like one system instead of five."
Alon Yair,
CTO at Onvego
Run mission-critical systems with confidence
Built for real-time speech applications where reliability, latency, and support matter.
- 99.9% uptime
Production-hardened infrastructure with monitoring and redundancy. - Sub-200ms real-time latency
Stream speech as it’s spoken — no waiting for sentence boundaries. - Priority support
Severity-based incident response with direct access to the Soniox team.

Use Soniox in popular frameworks




Privacy and compliance, built right in
Never stored, never saved.
Audio stays in memory, everything is processed in real-time.
Built for privacy-critical use cases.
SOC 2 Type II–certified and HIPAA-ready from day one.
Trusted where privacy matters most.
Used in industries where speech is sensitive — from healthcare to enterprise.



See how Soniox compares
Test Soniox side by side with Google, OpenAI, Azure, and more. Same audio. Same conditions. Live, transparent results.
Try Soniox Compare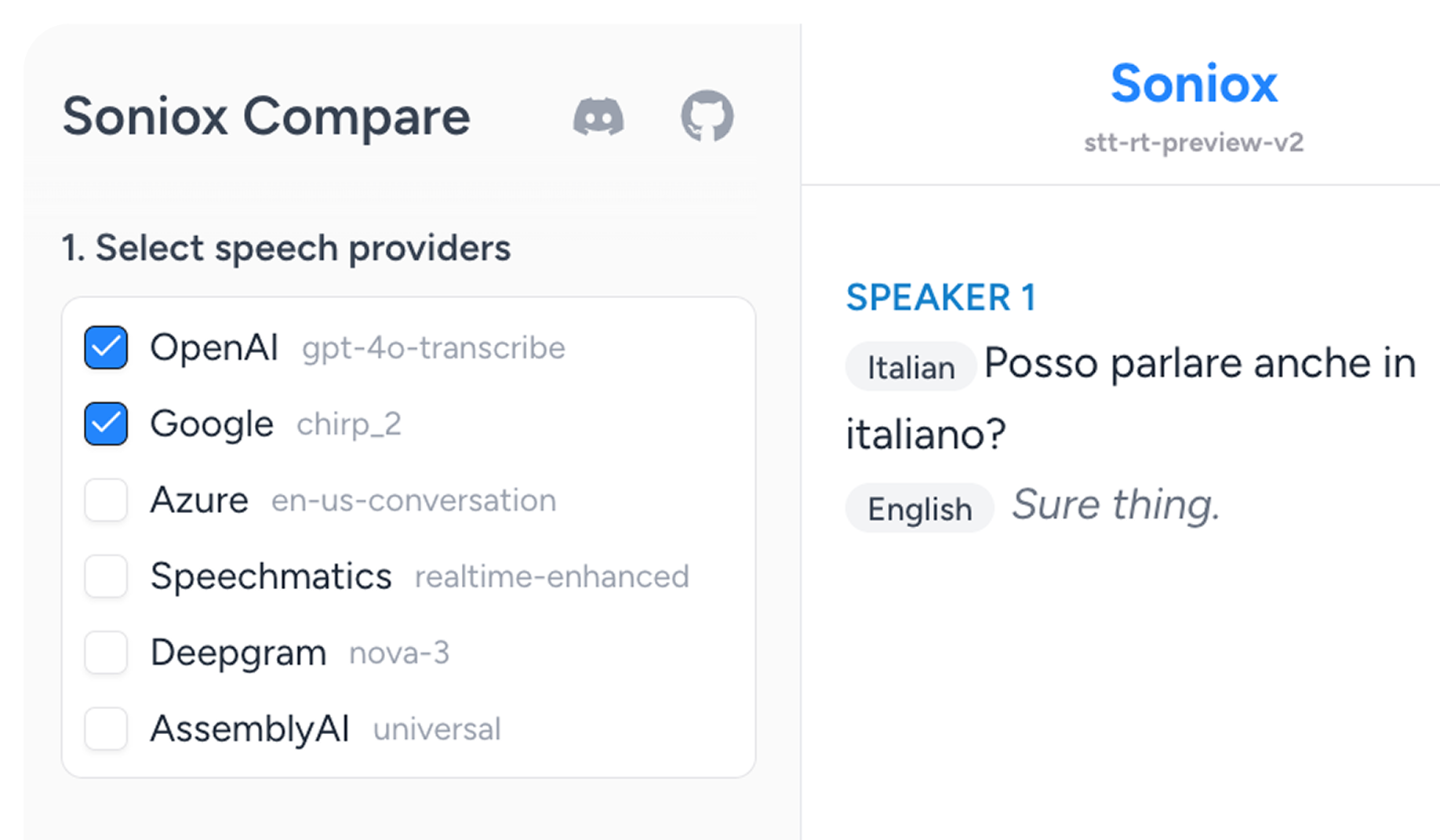
Go global with one API
Get production-ready speech-to-text recognition, transcription, and translation in 60+ languages.
Get started with the Soniox API
Explore docs
Find guides, API reference, and code samples to help you build fast.
docs_add_onView docsFrequently asked questions
Which languages does the Soniox API support?arrow_downward
Does Soniox require switching between models for different languages?arrow_downward
Can the Soniox API transcribe and translate speech at the same time?arrow_downward
Can Soniox handle language switching mid-sentence?arrow_downward
Is the Soniox API suitable for real-time and low-latency applications?arrow_downward
Is the Soniox API suitable for production and enterprise use?arrow_downward
- Scalable, production-hardened infrastructure
- Priority support with severity-based incident response
- Identical models and APIs across regions