World’s most accurate speech-to-text
Real-time speech-to-text and translation across 60+ languages, built for voice agents, live systems, and global products.
Trusted by teams building global voice products
Built for the hardest parts of speech recognition
Speech-to-text has improved dramatically for English, but most languages still do not have STT that is accurate enough for serious use.
Across much of the world, accents are misheard, names and numbers are transcribed incorrectly, and mixed-language speech falls apart. In noisy environments and multi-speaker conversations, error rates rise even further. And for real-time systems, latency and poor turn-taking still make voice experiences feel broken.
Soniox Speech-to-Text changes that. It is the first STT platform to deliver native-speaker accuracy across 60+ languages, with robust handling of multilingual and code-switching speech, precise recognition of alphanumerics and domain-specific terms, low-latency streaming, speaker diarization, and infrastructure designed for production scale.
Unmatched speech-to-text accuracy

Native-speaker accuracy
Unlike providers that mainly perform well in English, Soniox delivers native-speaker accuracy across 60+ languages, including dialects, accents, and mixed-language speech.
“It just gets the words right — any language, any accent, any context. That’s what accuracy is supposed to look like.”

Language switching mid-sentence
People often mix languages within a sentence or phrase. Soniox instantly detects language changes and transcribes every word in the correct language.
“It’s the first model we’ve used that actually understands Hinglish. Switching mid-sentence just works.”

Separate and identify speakers
Soniox separates and identifies speakers across 60+ languages, so transcripts stay organized, searchable, and clear even in fast-moving conversations.
“We tried a dozen speech-to-text and translation services. Soniox is the best, so that's what we use.”

Alphanumerics in any language
From phone numbers to reference IDs, Soniox recognizes alphanumerics exactly as spoken in any language, with precision down to the last digit and character.
“As Germany’s leading voicebot provider for automotive dealerships, Soniox has transformed our recognition of customer IDs and alphanumerics, driving much higher voicebot acceptance rates.”

Know when a speaker is finished
Soniox goes beyond silence detection, using tone, meaning, and conversational flow to detect when a speaker is truly finished. The result is faster, smoother, and more natural turn-taking.
“It’s so fast, captions appear before people even finish talking. Zero lag. No buffering. Nothing.”

Improve accuracy with context
Provide details like terminology, topic, participant names, or custom vocabulary to guide recognition toward the right words for your use case.
“Soniox captures complex medical terminology with high accuracy, helping physicians finalize notes faster and focus on patient care.”
Speech infrastructure for massive scale
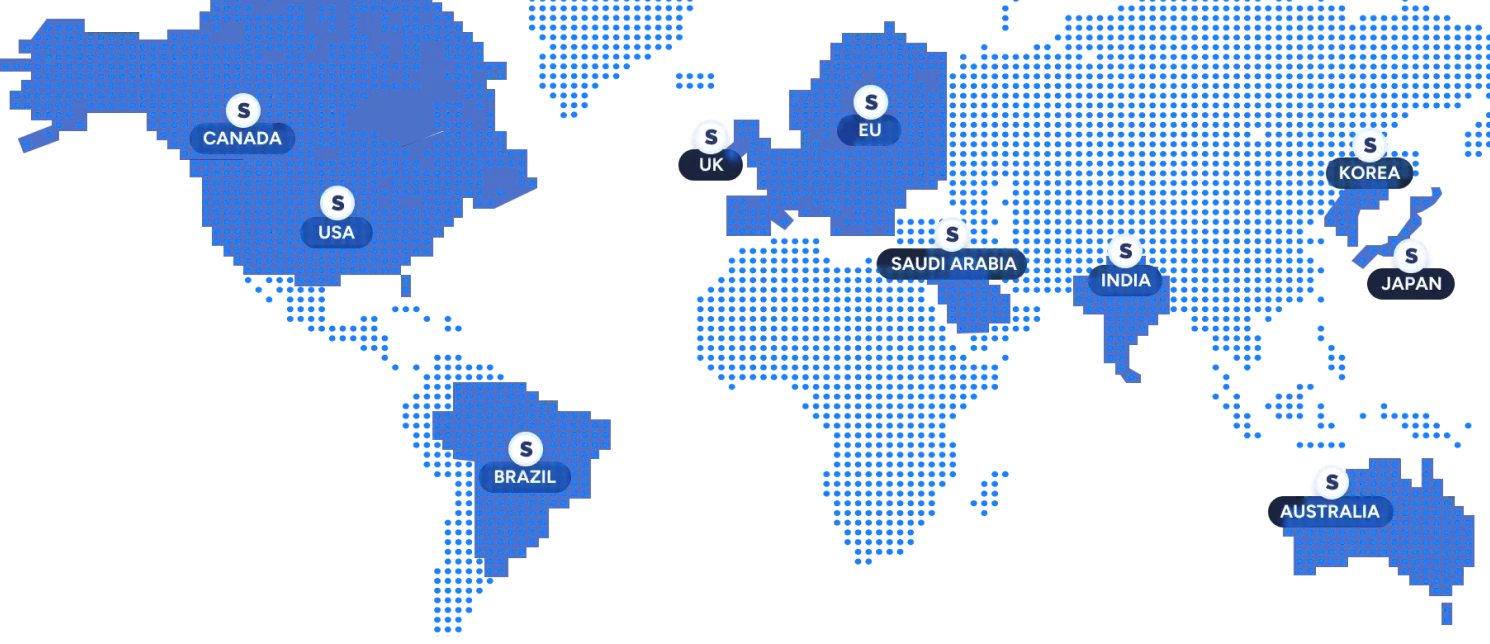
Build on one API and deploy in your region
Use the same models and API everywhere, with in-region processing to meet latency, data residency, and regulatory requirements.
Available: US, EU, Japan
Coming soon: Korea, Australia, Canada, India, Saudi Arabia, UK, Brazil
Run mission-critical systems with confidence
- 99.9% uptime
Production-hardened infrastructure with monitoring and redundancy. - Ultra-low-latency streaming
Process speech in real time with low latency for responsive voice applications. - Priority support
Severity-based incident response with direct access to the Soniox team.
"Before Soniox, our international users always had a noticeably different experience. Now accuracy and responsiveness match across all regions…it feels like one system instead of five."
Alon Yair CTO of Onvego
Estimate your speech-to-text cost
Choose real-time or async transcription and set your monthly audio volume to estimate your Soniox API cost.
Pricing calculator
Stop overpaying for speech AI
1,000 hours of audio / month
Pricing assumptions
Based on public pay-as-you-go pricing. Enterprise discounts and committed-use contracts may differ. Some providers charge separately for certain features. The calculator uses the public price for the provider configuration that most closely matches Soniox.
Use cases
Soniox is built for developers and teams who need accurate, real-time speech understanding at scale.
Call center
For contact centers that need real-time transcription, agent assist, and searchable records of every customer interaction.
Medical transcription
For healthcare platforms that need accurate transcription of clinical speech, including specialist terminology and patient documentation.
Media transcription
For media companies and content platforms that need fast, accurate transcripts of audio and video at any scale.
Speech analytics
For teams that need to extract insights, trends, and signals from large volumes of spoken conversation data.
Speech translation
For products that need real-time or batch translation of spoken content across 60+ languages with no loss of accuracy.
Voice agents
For developers building conversational AI products that need low-latency, high-accuracy speech input as their foundation.
Use Soniox in popular frameworks
Soniox integrates seamlessly with leading real-time communication platforms, AI frameworks, automation tools, and developer SDKs.
An open source framework and developer platform for building, testing, deploying, scaling, and observing agents in production.
Twilio is a cloud-based customer engagement platform (CPaaS) that provides APIs, allowing developers to integrate voice, messaging (SMS, WhatsApp), email, and authentication capabilities into applications.
Open-source development framework designed to build applications powered by large language models (LLMs).
The open-source AI toolkit designed to help developers build AI-powered applications and agents with React, Next.js, Vue, Svelte, Node.js, and more.
Open-source AI SDK with a unified interface across multiple providers. No vendor lock-in, no proprietary formats.
n8n is a powerful, low-code/pro-code workflow automation tool that connects various applications, APIs, and databases to automate tasks.
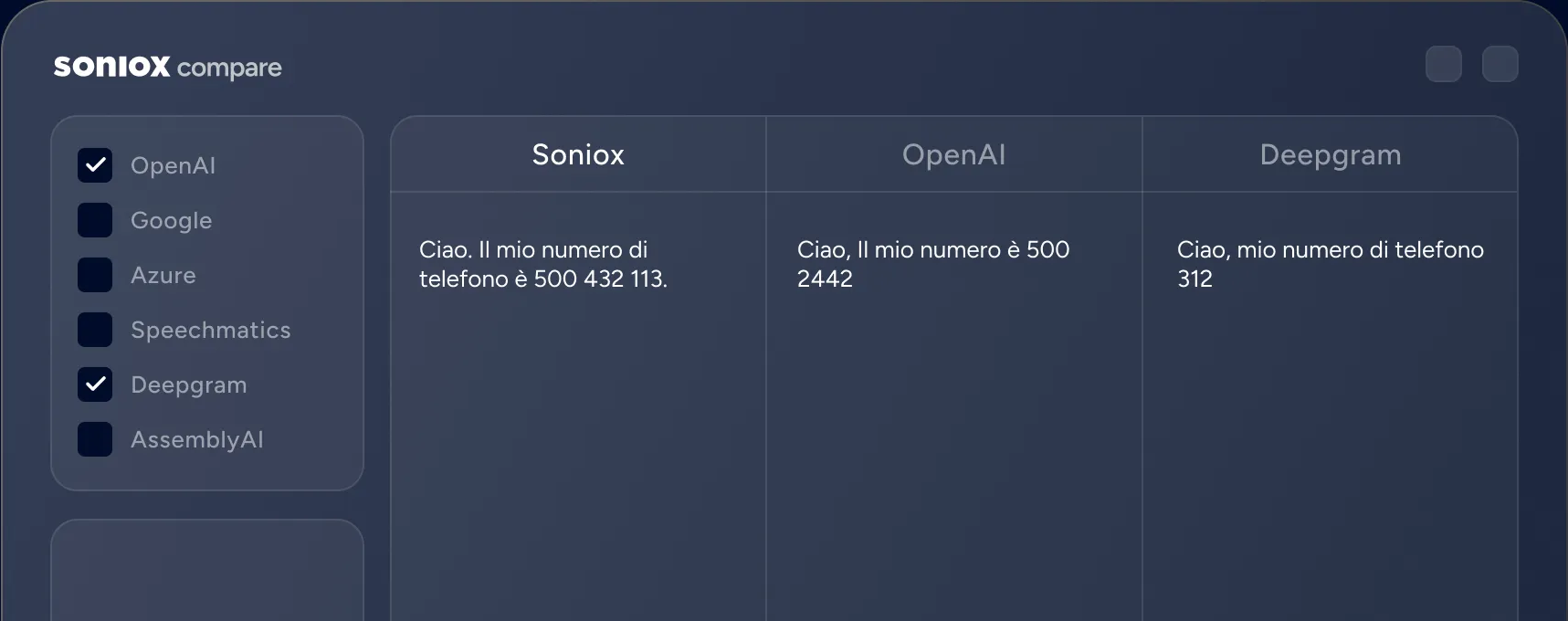
Compare Soniox side by side
Compare Soniox side by side with other providers across speech-to-text and text-to-speech. Live inputs. Transparent results.
Go global with one API
Get production-ready text-to-speech in 60+ languages.
Privacy and compliance, built right in
Never stored, never saved.
Audio stays in memory, everything is processed in real-time.
Built for privacy-critical use cases.
Adhering to leading global security, privacy, and compliance standards.
Trusted where privacy matters most.
Used in industries where speech is sensitive, from healthcare to enterprise.




Frequently asked questions
Which languages does the Soniox API support?
Does Soniox require switching between models for different languages?
Can the Soniox API transcribe and translate speech at the same time?
Can Soniox handle language switching mid-sentence?
Is the Soniox API suitable for real-time and low-latency applications?
Is the Soniox API suitable for production and enterprise use?
- Scalable, production-hardened infrastructure
- Priority support with severity-based incident response
- Identical models and APIs across regions
How does Soniox perform with noisy or real-world audio?
Can Soniox distinguish between different speakers?
How does Soniox handle privacy and data security?
Can I customize accuracy for my domain or use case?
How hard is it to integrate the Soniox API?
How do I get started?
Ready to get started?
Create an account instantly, or contact us to design a custom package for your business.
Build with APIDocumentation
Get up and running in minutes and spend your time building, not wrestling with the API.
Explore docsSee what you’ll pay
Pay only for what you use with our flexible pricing. Built to scale with you.
Pricing details